

執筆時点で話題となっているテキスト生成AI「ChatGPT」や画像生成AI「Stable Diffusion」などの生成AI(Generative AI)はそもそもどのような仕組みなのだろうか?
できるだけ難しい言葉を使わずにざっくりと解説する。
目次
はじめに
現在のAI(Artificial Intelligence)は第三次ブーム以降のものです。
「第三次」と言っているように、「第一次」「第二次」のブームのものも有った訳ですが、本稿では取り扱いません。
「AI搭載」と言っても「第一次」「第二次」の頃のレベルのものでも間違いとは言えないことだけ注意してください。
テキスト生成AI「ChatGPT」や画像生成AI「Stable Diffusion」などの生成AI(Generative AI)は、機械学習型(Machine Learning)AIを使っています。
この機械学習型AIの仕組みをできるだけ難しい言葉を使わずにざっくりと解説します。
ざっくりと解説する関係上、正確には違う部分があったり、最新でなかったりする部分があるかと思いますがご了承ください。
また私も間違えて覚えてしまっている部分があるかと思いますので、その時はコメントで指摘して頂けると幸いです。
そもそも人間の認識とは?
機械学習型AIの解説の前にそもそも人間はどのように物を認識しているのでしょうか?
たとえば、「聞いたこと」も「見たこと」も「食べたこと」も無い新しい食べ物があったとします。
この新しい食べ物の名前を聞いたとき「何々みたいな名前」、見た目についても「何々みたいな形や色をしている」、食べてみて「何々の味に似ている」などのように、感想を述べると思います。
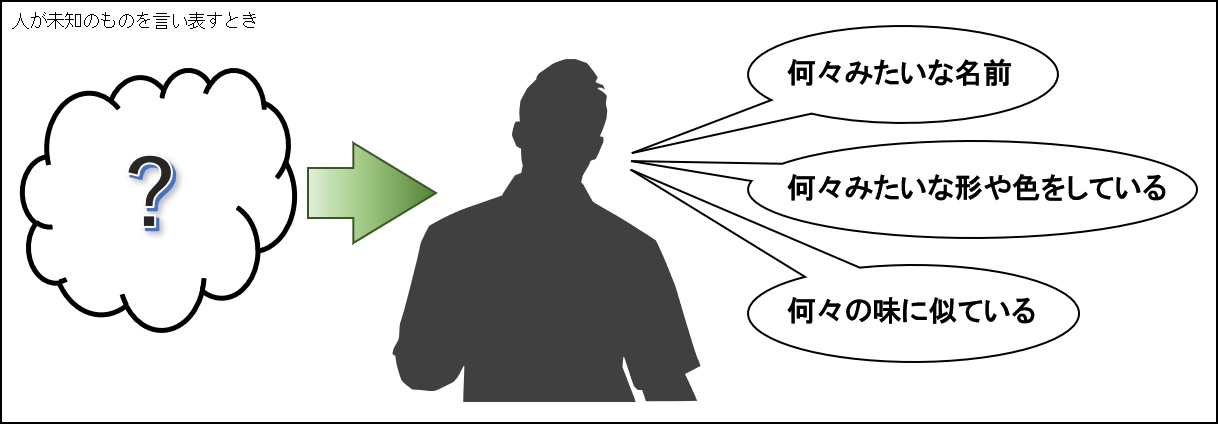
このように、今までに聞いたもの、見たもの、食べたものを「学習(トレーニング)」した経験により似たものを記憶から引き出し照らし合わせる「推論」を行って、感想を述べます。
このようなことをコンピュータで実現しようと言うのが機械学習型AIです。
機械学習型AI
機械学習型AIは、上記で示したように、「学習(トレーニング)フェーズ」と「推論フェーズ」があります。
学習フェーズは、主にクラウド/サーバー側で動作し、推論フェーズは、エッジ(クラウド/サーバーのユーザに近い部分)や端末(PCやスマホ)で動作します。
学習フェーズ
テキスト生成AIだったらテキストを、画像生成AIだったら画像の情報を学習するために、とにかく大量に入力を必要とします。
プログラミングテクニック アルゴリズム+データ構造=プログラム でも言っていますがコンピュータは情報を元のまま扱えるケースは少なく、「情報をデータに変える」、つまりモデル化が必要です。

例えば、画像生成AIで画像を学習するときを考えてみましょう。
今、学習元の画像がINF-0からINF-nまで大量にあったとして、それぞれを繰り返しまたは並列に処理していきます。
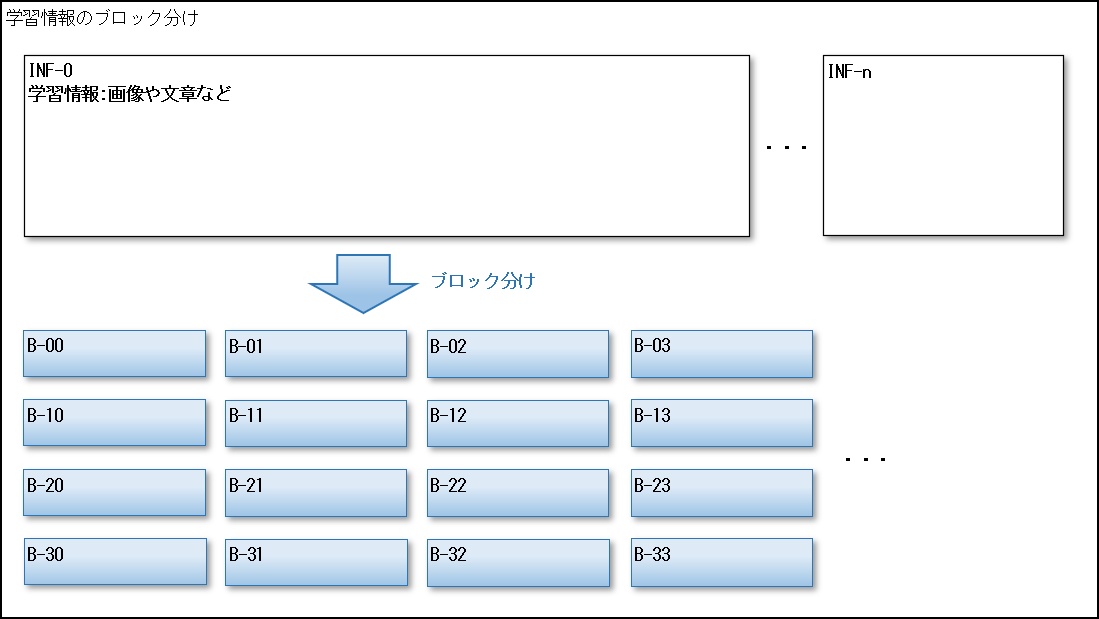
まず例にした学習用情報は縦横のサイズがまちまちなため、処理しやすいようにブロック分けを行います。
画像の場合は、8×8ピクセルや16×16ピクセルなどの様に単純なサイズで区切られることがあります。
テキストの場合は、単語や文章や文節など用途やフィルタによって区切られる場合があります。
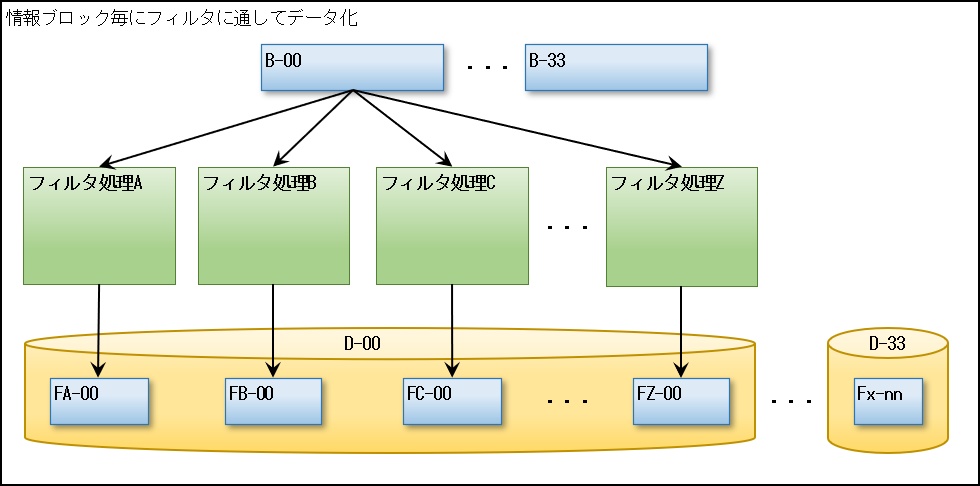
次にそのブロック毎(B-00~B-33)にさまざまなモデル化の手段として多種類の「フィルタ」を通してコンピュータで扱えるようにデータに変換していきます。(ここではその画像が何の画像なのか(例えば猫の画像)、どのような状態なのかなどのテキスト情報用のフィルタも含みます)
例えば画像フィルタとして、実際には使われて無いかもしれませんが、青色のセロファンを通して画像を見ると青の部分がフィルタリングされて、赤と緑の部分が協調でき、そのデータを抽出することができます。
※コンピュータで扱う色は光の3原色RGB: Red Green Blueが基本です。
これは、単なる一例でしかありませんが、このような「フィルタ」を多種類(フィルタA~Zなど)利用することで、入力された「情報をデータ(FA-00~FZ-00)として昇華」します。
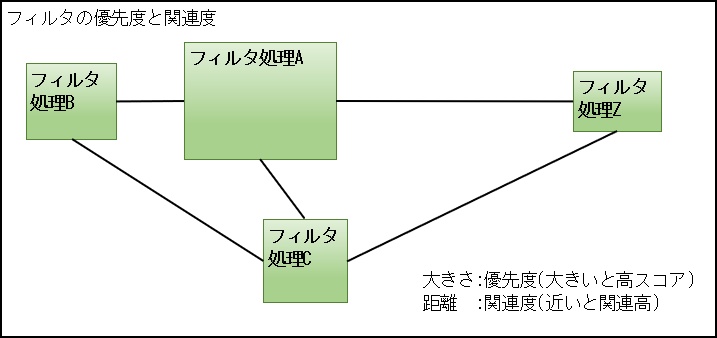
もちろん「フィルタ」の中には優先度(スコア化)や関連性が高いものや低いものまでさまざまなものがあり、フィルタリングしたデータもそれに従い1つのデータのグループ(D-00)にまとめられます。
ブロック毎(B-00~B-33)に処理するのでデータのグループ(D-00~D-33)も個別に作成されます。
さらにこのグループ分けしたデータをさらに別のフィルタで多段階的にデータ化することもあります。
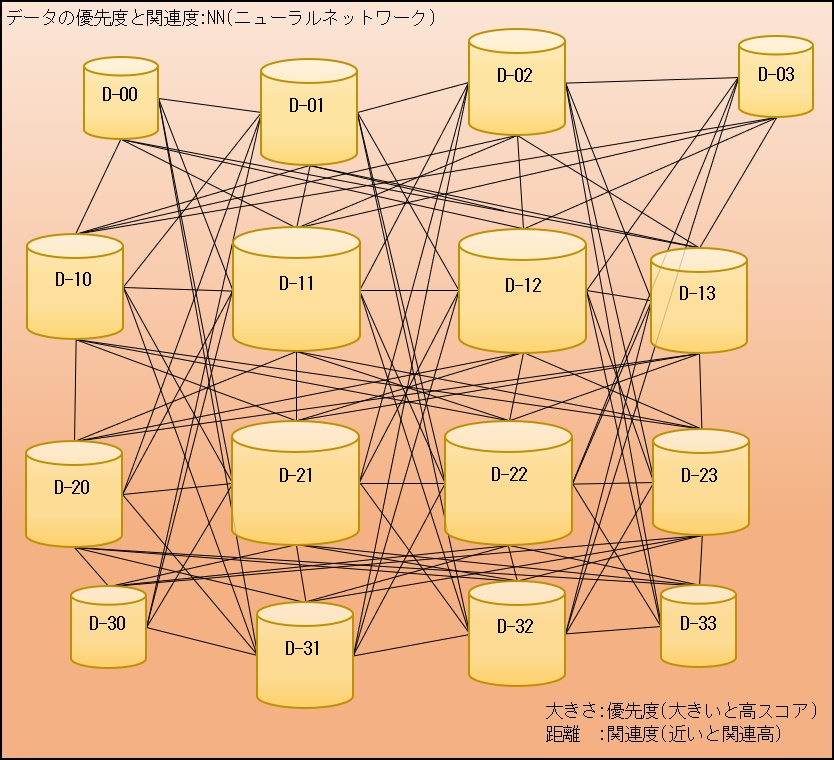
作成したデータ群(データのグループ)は、優先度や関連度から上記の図に表すことができ、これらをニューラルネットワークと呼んでいます。
元の情報の各ブロックと、それから得られたデータ群をデータベースなどに格納して、推論フェーズで利用可能な状態にします。
情報をデータに昇華する「フィルタ」によるモデル化は、様々なアルゴリズムが存在しており、テキスト用(ChatGPTなど)と画像用(Stable Diffusionなど)で使う「フィルタ」や作成した「ニューラルネットワーク」は違うだろうと想像できます。
人間の脳だってテキスト(=言語)を処理する部分と、画像を処理する部分は別の場所と言うのを聞いたことがあるかと思います。
テキスト生成AIと画像生成AIが別々に作られているのはこれが理由の1つだと言えます。
また、プログラミングテクニック アルゴリズム+データ構造=プログラム でも言っていますが、今までは情報をデータに昇華しきれずに、劣化させてしまっていた部分が多かったため生成されたものを人が見ると「何か違う?」となっていたのですが、それが、やっと問題が少ない範囲で劣化させることが無くなってきたと言えます。
補足:データの劣化を防ぐために「教師あり学習」と言う手法もありますがここでは割愛します。
その他、執筆時点で「ChatGPT」は、その中核にGPT-1, GPT-2, GPT-3, GPT-4 と呼ぶ言語モデルがありますが、世間に認知されるようになったものはGPT-3以降です。
このことからGPT-1, GPT-2は学習用の情報量の少なさやフィルタの質も関連して、情報をデータに昇華しきれずに、劣化させてしまっていた部分が多かったためだと推測します。
もちろん、「フィルタ」を多数利用すると共に「フィルタ」の出力精度を向上させるためには、コンピュータのマシンパワーが多く必要であり、それが近年のGPU(GPGPU)やAI専用プロセッサの発展により実施可能となったため、GPT-3やGPT-4が実現できたのだと考えます。
推論フェーズ
推論フェーズでも、基本的なフィルタ処理の部分は学習フェーズと変わりません。
違うのは、その演算精度で、学習フェーズでは32bit(FP32=浮動小数点型32bit)や64bit(FP64)などが利用されるのに対して、推論フェーズでは、16bit(FP16,BF16=指数部と仮数部の比率が違う浮動小数点型16bit)や8bit(INT8:整数型8bit)などが利用されます。
演算精度に違いがあるのは、学習フェーズで利用した情報とまったく同じものを推論フェーズの入力に利用することが無いと言えること。
また、優先度(や関連度も含む場合もある)によるスコア化により、正解を1つだけ出力することよりも、スコア上位のものをいくつか提案する形の出力が可能なためです。
学習フェーズの方は演算精度が高い分、マシンパワーも高いものが必要であり、消費電力も多く必要です。
スマホなどに搭載されているAIエンジンと呼ばれるものは、推論フェーズ用のものであり、少ない消費電力で処理可能なもので、学習用に利用することを前提としていません。
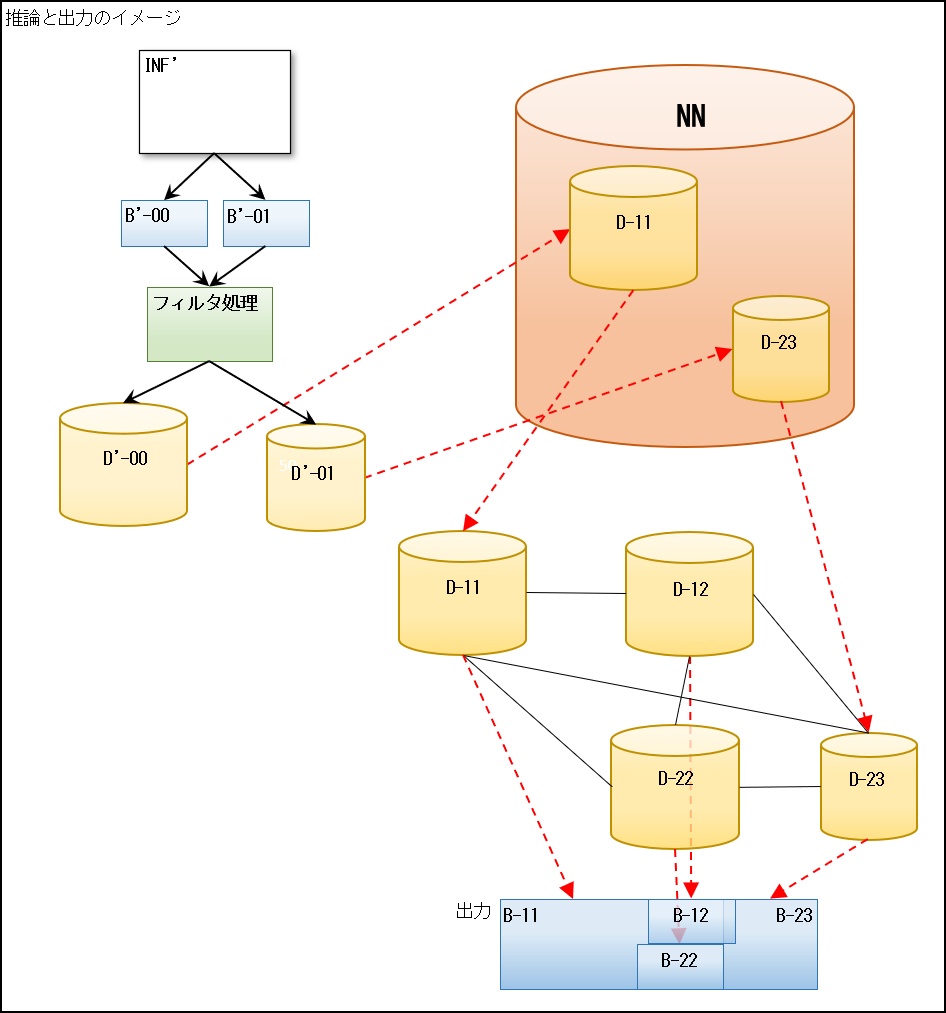
画像生成AIの場合は、入力はテキストであり、画像を入力するわけではありませんが、テキスト情報に関連したフィルタを用いてデータに昇華します。
図の例では情報INF’を入力したとき、それをブロック化B’-00,B’-01にしてそれぞれフィルタ処理し、D’-00,D’-01が得られた時、そのデータとニューラルネットワーク(図ではNN)のデータと照らし合わせて、優先度(スコア)が高いものが、それぞれD-11とD-23だったとします。
D-11とD-23は単なるデータなので、元の情報のレベルに戻してから出力しなければなりません。
D-11とD-23の元の情報である、B-11とB-23を単にくっつけて出力しても、それなりのものになる可能性がありますが、まあ多くは「何か違う?」となってしまいます。
このため、図の例ではD-11とD-23の間にある関連したD-12とD-22も取得し、それぞれの元の情報である、B-12とB-22を融合(ブレンド)させ、全体を均した出力とすることにより、上記の「何か違う?」と言う違和感を軽減します。
AIが対象とするものにもよりますが、「図の例ではD-11とD-23の間」だけを取得しましたが、その他にも周りには関連する情報があります。
一段先や二段先などその関連度に応じて少しずつ融合(ブレンド)させれば、より違和感の少ない出力が得られることが可能となります。
優先度(スコア)が1番高いものだけではなく、高い方からいくつかその度合いに応じて融合(ブレンド)させることでも違和感が少ないものを作ることが可能となります。
しかしながら、融合させるための工程や情報が多いほど演算性能や消費電力など多くのリソースが必要となってしまうことに注意が必要です。
このため、生成AIでは16bitや8bitの推論ではリソースが足りずに32bitなどで行うことが多いようです。
あと、「情けは人の為ならず」や「風が吹けば桶屋が儲かる」と言うことわざなどは、直接関係もないこと/ものが回りまわって繋がっていることを表すものですが、AIの対象によりますが、あえて、関連性が低い(だが繋がりはある)ものを組み合わせて出力する場合もあります。
機械学習型AIの問題点
学習するためには大量の情報の調達が問題となることがあります。
本サイトでも時々言っていますが、「無料で公開していますが著作権を破棄したわけでありません」がその1つです。
インターネット上にある「もの」は無料で公開してあるものが多くありますが、それを2次利用するには著作権者に許諾を受けなければなりません。
無料で見られるからと言って、自由に使ってよいと言うわけではないのです。
大量に必要だからと言って、無断で利用したら、著作権の侵害/著作権法違反となります。
コンプライアンスとは「法令遵守」のことですが、上記は明確にコンプライアンスに反しています。
以下、余談なので飛ばして頂いても可です。
本サイトは、記事投稿によるブログ形式のものが主体です。
独自にサーバー(AWS Lightsail利用)を立てている理由の1つが知的財産権(著作権含む)の取り扱いを容易にするためです。
どこかのサイトを借りて記事を投稿する場合、記事の著作権はサイトにもよりますが、サイト側に帰属しなければならない場合やサイト側がデータ収集などで分析することを予め契約内容に告知している場合があります。
きちんと契約内容を把握していないために問題となっては困ります。
知的財産権(著作権含む)は、守るべきものは守る、主張すべきものは主張するが基本であり、独自サーバーのレベルとすることで、本サイトはその扱いを容易、つまり一次ソースにできることを明確にしています。
もちろん別の理由として、制限がほとんどない独自サーバーなら、ツールの形で実際に動くプログラムを公開できるためでもあります。
生成AIでシンギュラリティが起きたのか?
シンギュラリティとは、「特異点」のことで、AIを含むコンピュータに関して用いられる場合、コンピュータが人間を超える点のことを意味します。
では、生成AIでシンギュラリティが起きたのでしょうか?
上記の機械学習型AIの仕組みから次のことが言えます。
- 学習フェーズ
情報をデータに昇華するために、フィルタを多種類利用するが、その質や量などはまだまだ試行錯誤してテクニックやノウハウなどを蓄積している状態である。 - 推論フェーズ
入力情報から作成したデータと学習データを照らし合わせるが、何をもって高スコアとするのか?
データのまま出力するわけにはいかないので元の情報の断片をより違和感のないように融合させなければならない
など、こちらも試行錯誤してテクニックやノウハウなどを蓄積している状態である。
執筆時点で、各生成AIのソースコードは公開されてないと思いますが、上記はまだまだ人手で作っていると思います。
AI自体を作れる側から見るとまだまだ手のかかるものであるということが言えます。
逆に言えば、上記自体をAIができるようになると、AI自体がAIを創造することが可能となります。
創造AI : Creative AI : クリエイティブAIは既に別の意味で使われているようなので、ここでは、進化するAI : 進化AI : Evoltive AI : エボルティブAIと呼ぶこととしますが、現在はまだその段階まで来ていないと思います。
そもそも、PCやスマホは、ある特定の項目では、人よりも遥かに高性能ですよね?
生成AIの出力が人間と同等かちょっと超えたぐらいでは、シンギュラリティは発生したと言えないと思います。
しかし、進化AIが実現できれば、それは人の手を離れ独自に進化することが可能です。
この状態になって、初めて「シンギュラリティ」に到達することができる条件の1つが揃うと私は考えます。
しかし、進化AIを満足ができる時間で処理できるようにする(何年もかかっては意味がない)ためには、マシンパワーももっともっと必要であり、「シンギュラリティ」に到達することができる条件を満たすマシン(H/W)が出現するまでにはまだまだ年月がかかりそうだと言うのが私の見解です。
その他に言えることは、我々人間も繰り返し学習したことはすぐに出てきますが、あまり学習してないことはなかなか出てこないと言うのがあります。
よく人は「覚えていない」=「記憶してない」なんて言いますが、実際には記憶自体はしていて、単に引き出せないだけだそうで、何かのきっかけで、記憶がよみがえることがその証拠の1つだそうです。
人はこのように繰り返し学習したことは引き出しやすいですが、機械学習型AIは学習したデータを引き出すことは人よりも長けています。
しかしながら、機械学習型AIも人と同じで学習時に入力する情報によく出てくることに対して推論する最大公約数的なことは得意(高スコア)ですが、入力情報にあまり出てこないことに対しては不得意(低スコア)ということです。
あと、嘘の情報でも学習情報として量が多いと推論時のスコアが高くなってしまうと言う問題もあります。
機械学習型AIの作りにもよりますが、この世に存在しないまったく新しいものを創造するとかの場合では、あえてスコアの低いものをランダムに融合させるなどして、突然変異が起こる仕組みが必要かもしれません。
そういう意味でもシンギュラリティは起きてないと思います。
最後に
今回AIの基本的な仕組みを紹介しました。
ざっくりですが、機械学習型AIおよび生成AIの基本的な仕組みをご理解いただけたでしょうか?
ものによって実装はこの記事のものから外れる場合があるかもしれませんが、基本的な仕組みはこのような感じです。
AIをブラックボックスの得体の知れないものとして見てしまい、必要以上に脅威に感じている方が多いのではないでしょうか?
やはり対象のAIの仕組みをざっくりとでも知った上でその性質を理解できると、脅威に感じる方は少なくなるではないでしょうか?
執筆時点で各生成AIのソースコードは公開されてない(オープンになってない、透明性がない)と思いますが、既に進化AIを実現できていた場合は、私でも脅威と感じるかもしれませんが・・・
また、本稿は、「ざっくりと解説」であるため、実際に機械学習型AIの詳細を詰めて実装するとなると、並々ならぬ努力が必要となります。
ですが、AIの仕組みを解説することで、現在のAIを必要以上に脅威に感じる必要がないことを理解頂けるのではないかと考え執筆しました。
機械学習型AIはまだまだ発展途上だと思います。
AIへの興味や、少しでもAIの仕組みの理解の助けになれば幸いです。
ご意見、ご要望、不具合などのご連絡
ご意見、ご要望、不具合などのご連絡は次からお願いします。
- コメント
本投稿へ下部の コメントを書き込む からご連絡ください。
コメントは承認方式となっており、当方が承認しないと公開表示されません。
公開表示を希望されない方はその旨コメントに記述ください。 - Twitter
ご連絡は @dratech2020 https://twitter.com/dratech2020 の該当ツイートに返信するか、ハッシュタグ「#プログラミングの深淵を求めて」を付けてツイートしてください。 (すぐに気が付かない場合がありますので、ご了承ください)
関連投稿

- 「いいね」のお願い (2023/06/02 停止中)
本投稿記事を読んで「いいね」と思った方は是非下記から投票をお願いいたします。


コメント